Vector databases are having a breakout moment. Data from Google and GitHub show how the world of vector databases is booming, with search volumes and repository activity reaching all-time highs from near zero just a few years ago.
Vector databases represent information as lists of numbers, known as vectors. Each number in a vector represents a feature of the underlying data. Complex data, like images, audio, and text, can be vectorized to allow more advanced searches and comparisons across them. For example, the vector representations of an image of a bunny and an image of a puppy will be more similar to each other than to that of a cargo ship. Bunnies and puppies share more visual features—such as being fluffy and cute—than they do with watercraft.
Vector databases open the door to all kinds of powerful new features in software used every day. They are often used for better search tools and recommendation engines. Today with the rise of large language models, vector databases are increasingly used for retrieval-augmented generation, known as RAG. RAG helps developers improve responses from LLMs by first searching for relevant information in a separate knowledge base—like a company's blog or internal documentation—and then providing that as context to the LLM.
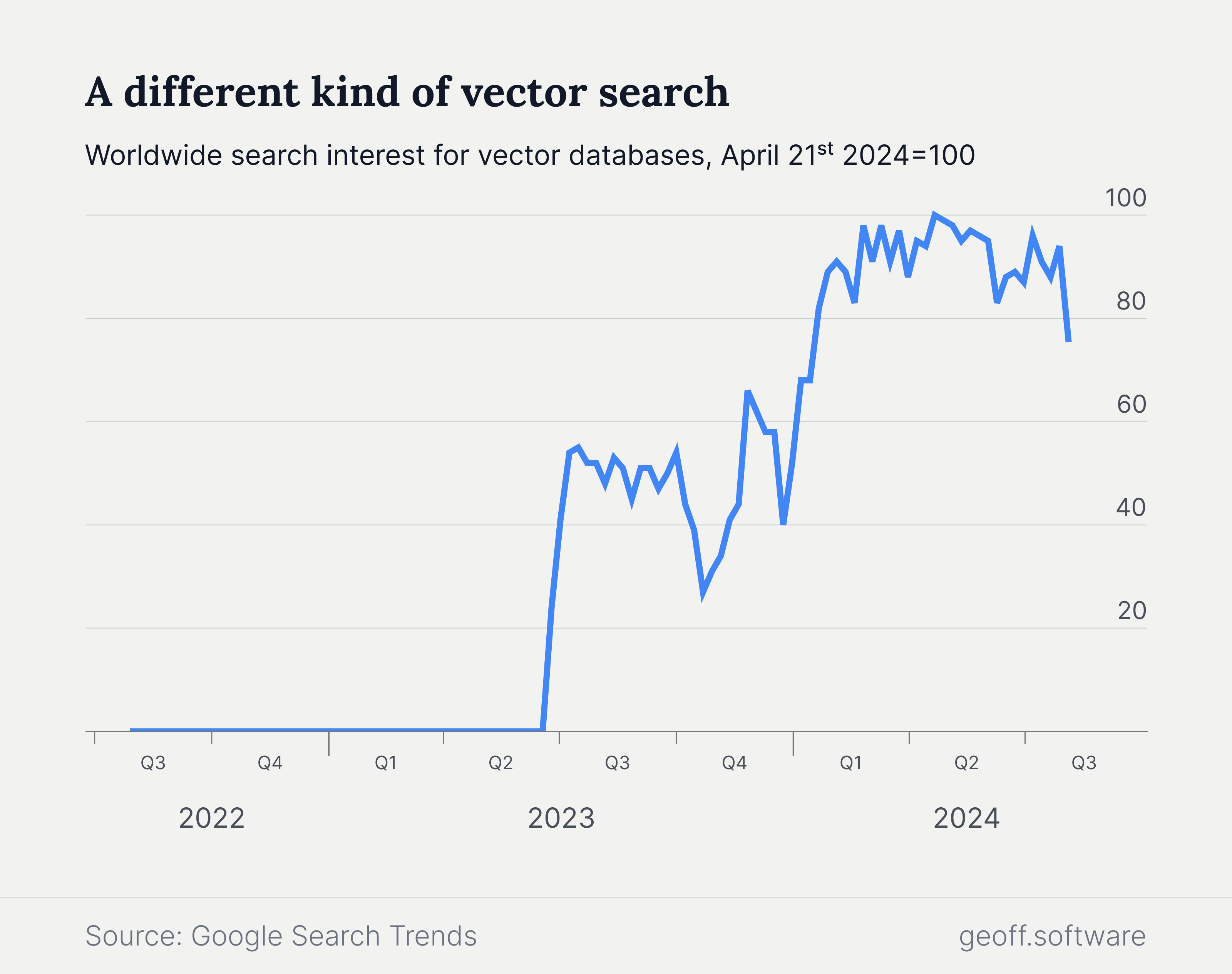
Developers are taking notice. Search volume data from Google shows how interest in vector databases has surged since mid-2023. Searches peaked in April of 2024, but remain far above long-term trends.
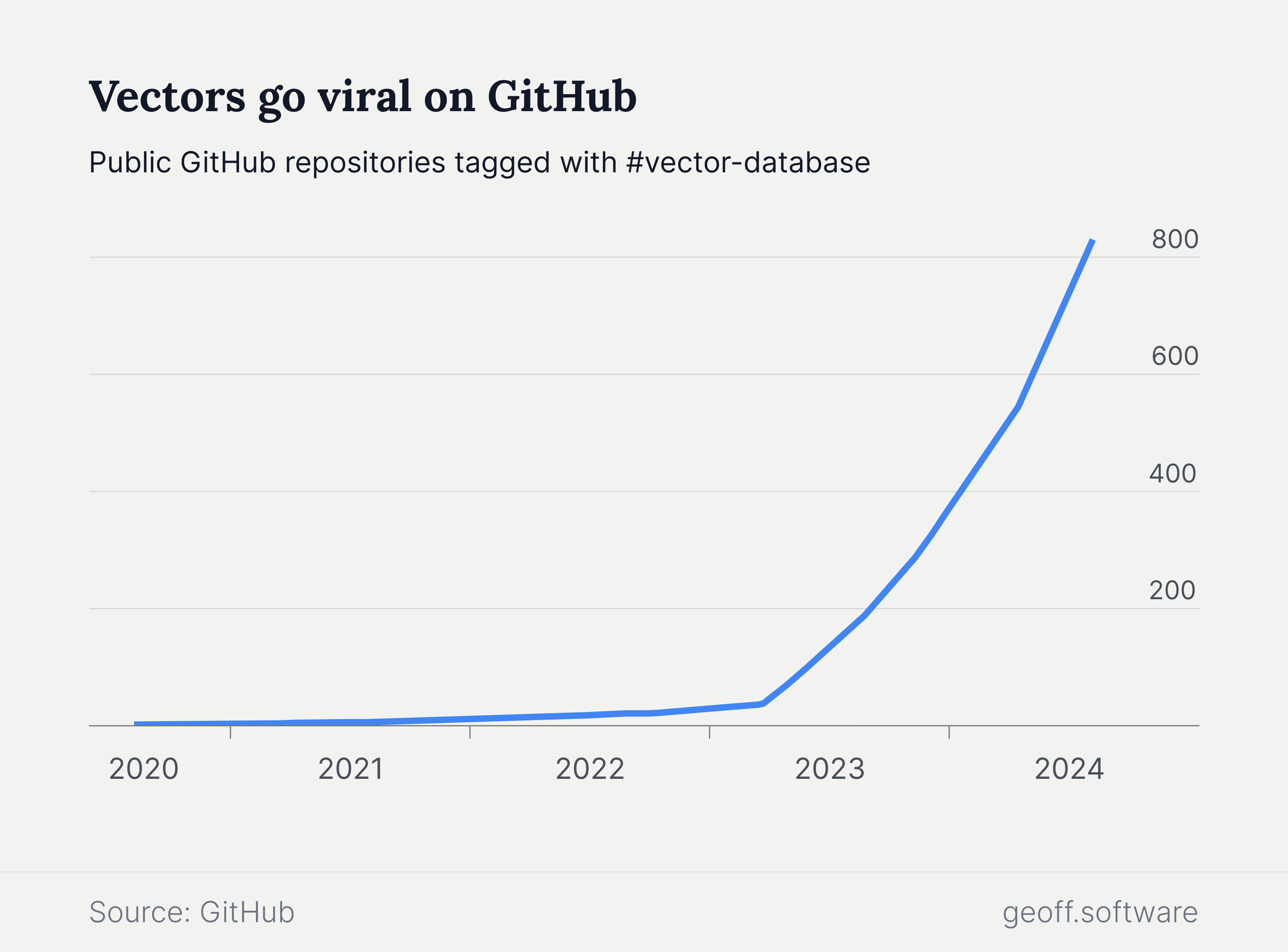
Developers are not only searching for vector databases. They are also building out an entire ecosystem of open source tools and resources around them. The number of open source repositories related to vector databases has grown from virtually zero to over 800 in just four years.
A few maintainers of popular open source projects have attracted venture funding. One such company, Zilliz, most recently raised $60m in Series B funding. The GitHub repository for the company's cloud-native vector database, called Milvus, boasts more than 28k stars. The company behind Qdrant, a vector similarity search engine and vector database, raised $28m in Series A funding in early 2024. In their announcement, the Qdrant team pointed to "a paradigm shift underway in the field of data management and information retrieval."
Will the recent burst of vector enthusiasm yield big changes to AI or simply peter out? As the largest online community for developers, GitHub has a knack for creating and incubating communities for nascent technologies. As the home of upstart vector databases, it has the potential to turn viral growth into real productivity for AI software developers.