Software developers and AI engineers have much in common. For one, they are prolific when it comes to sharing their work. GitHub, the de facto home for the world's open source code, boasts more than 175 million publicly available repositories — the collective output of 85 million developers. Hugging Face, an online platform for sharing AI models and datasets, hosts over a million models shared by more than 1.5 million users.
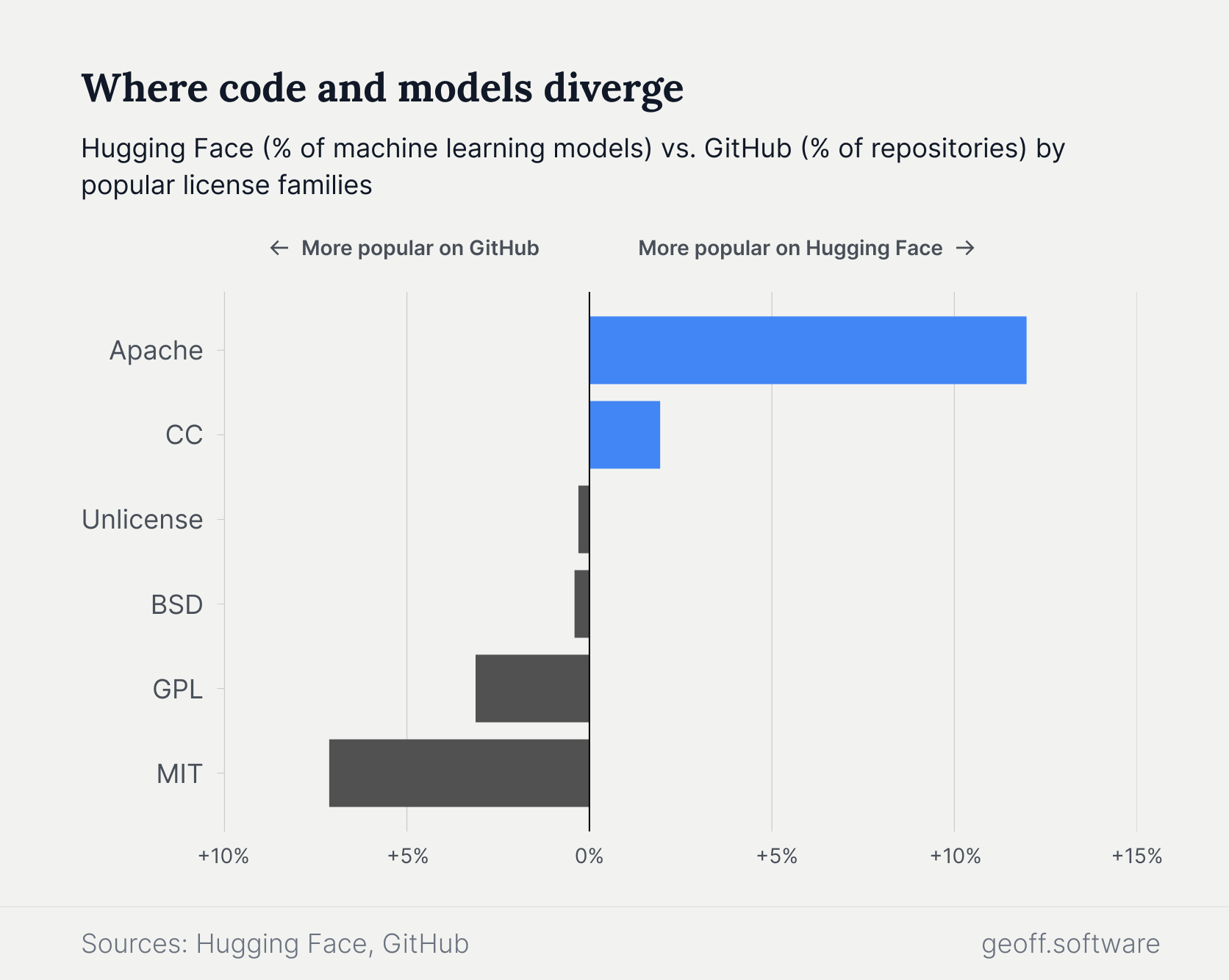
Software developers and AI engineers share another passion: licensing. Models and code share many of the same licenses from popular license families, like Creative Commons (CC) and GNU General Public License (GPL). Relative popularity can vary greatly between the two platforms. As a percentage of all models or repositories, Apache licenses are far more common on Hugging Face than GitHub. MIT licenses, however, follow the opposite trend.
The MIT license is simpler and shorter than the Apache license, which includes more explicit restrictions around trademarks and patents on derivative projects. The Apache license offers a dash more protection for AI models that might involve patentable innovations.
Artificial intelligence — and particularly the explosion of its open source variants — has led to the creation of new AI-focused licenses to address some of the issues raised by the deluge of new models. Of the top ten license families on Hugging Face, three (Llama, Gemma, and RAIL), are designed specifically for AI models.
Llama and Gemma, created by Meta and Google respectively, are not considered by many to fit the technical definition of open source provided by the Open Source Initiative — a group that bills itself as the leading voice on open source policies and principles. Even so, definitions and licenses are quickly changing. Recent updates to the Llama license are more permissive and in line with Zuckerberg's plan to make AI follow in the footsteps of software's most successful open source project, Linux.
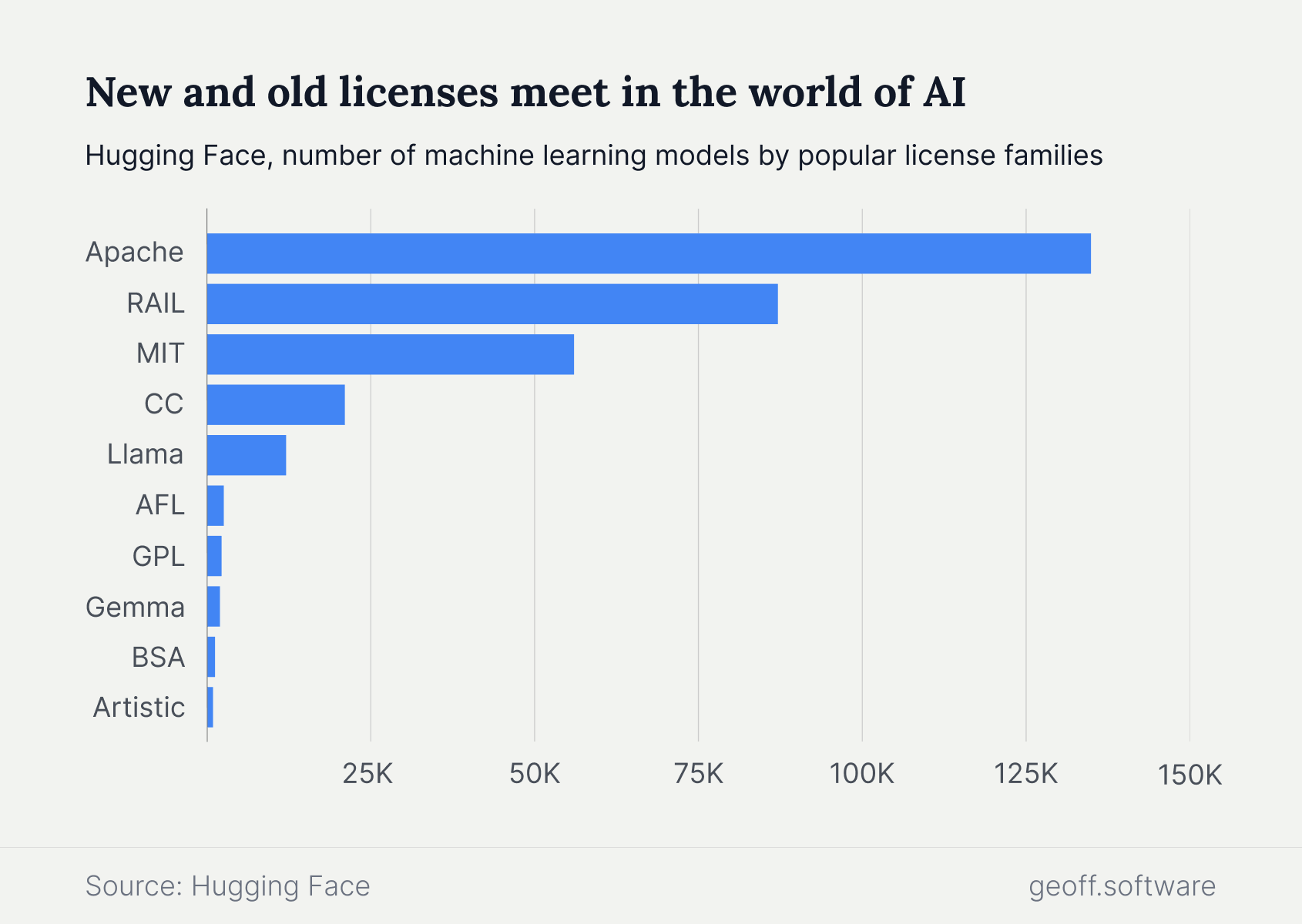
RAIL, short for Responsible AI Licenses, is a collection of licenses that restrict how others can use models. According to the team behind the RAIL licenses, they are designed to "empower developers to restrict the use of their AI technology in order to prevent irresponsible and harmful applications". Users of these license can limit certain uses, such as surveillance and crime prediction, while freely allowing others.
Some experts worry about what's known as 'license proliferation'. An abundance of similar licenses sows confusion in the AI community. Others argue that machine learning models come with specific requirements and needs, different from those of code. The non-deterministic nature of AI means it can replace functions where human oversight was once required. Important decisions do not need to be written in code. AI and LLMs can make decisions on the fly — their outputs changing each time.
As with code, the debate around open source AI will likely remain contentious. Lessons from GitHub's community hint at a similarly bright, yet complicated, future for Hugging Face.